MadMiner physics tutorial (part 3C)#
Johann Brehmer, Felix Kling, Irina Espejo, and Kyle Cranmer 2018-2019
In part 3C of this tutorial we will train a third neural estimator: this time of the likelihood function itself (rather than its ratio). We assume that you have run part 1 and 2A of this tutorial. If, instead of 2A, you have run part 2B, you just have to load a different filename later.
Preparations#
import logging
import numpy as np
import matplotlib
from matplotlib import pyplot as plt
%matplotlib inline
from madminer.sampling import SampleAugmenter
from madminer import sampling
from madminer.ml import LikelihoodEstimator
# MadMiner output
logging.basicConfig(
format='%(asctime)-5.5s %(name)-20.20s %(levelname)-7.7s %(message)s',
datefmt='%H:%M',
level=logging.INFO
)
# Output of all other modules (e.g. matplotlib)
for key in logging.Logger.manager.loggerDict:
if "madminer" not in key:
logging.getLogger(key).setLevel(logging.WARNING)
1. Make (unweighted) training and test samples with augmented data#
At this point, we have all the information we need from the simulations. But the data is not quite ready to be used for machine learning. The madminer.sampling class SampleAugmenter will take care of the remaining book-keeping steps before we can train our estimators:
First, it unweights the samples, i.e. for a given parameter vector theta (or a distribution p(theta)) it picks events x such that their distribution follows p(x|theta). The selected samples will all come from the event file we have so far, but their frequency is changed – some events will appear multiple times, some will disappear.
Second, SampleAugmenter calculates all the augmented data (“gold”) that is the key to our new inference methods. Depending on the specific technique, these are the joint likelihood ratio and / or the joint score. It saves all these pieces of information for the selected events in a set of numpy files that can easily be used in any machine learning framework.
sampler = SampleAugmenter('data/lhe_data_shuffled.h5')
# sampler = SampleAugmenter('data/delphes_data_shuffled.h5')
03:42 madminer.analysis INFO Loading data from data/lhe_data_shuffled.h5
03:42 madminer.analysis INFO Found 2 parameters
03:42 madminer.analysis INFO Did not find nuisance parameters
03:42 madminer.analysis INFO Found 6 benchmarks, of which 6 physical
03:42 madminer.analysis INFO Found 3 observables
03:42 madminer.analysis INFO Found 89991 events
03:42 madminer.analysis INFO 49991 signal events sampled from benchmark sm
03:42 madminer.analysis INFO 10000 signal events sampled from benchmark w
03:42 madminer.analysis INFO 10000 signal events sampled from benchmark neg_w
03:42 madminer.analysis INFO 10000 signal events sampled from benchmark ww
03:42 madminer.analysis INFO 10000 signal events sampled from benchmark neg_ww
03:42 madminer.analysis INFO Found morphing setup with 6 components
03:42 madminer.analysis INFO Did not find nuisance morphing setup
The SampleAugmenter class defines five different high-level functions to generate train or test samples:
sample_train_plain(), which only saves observations x, for instance for histograms or ABC;sample_train_local()for methods like SALLY and SALLINO, which will be demonstrated in the second part of the tutorial;sample_train_density()for neural density estimation techniques like MAF or SCANDAL;sample_train_ratio()for techniques like CARL, ROLR, CASCAL, and RASCAL, when only theta0 is parameterized;sample_train_more_ratios()for the same techniques, but with both theta0 and theta1 parameterized;sample_test()for the evaluation of any method.
For the arguments theta, theta0, or theta1, you can (and should!) use the helper functions benchmark(), benchmarks(), morphing_point(), morphing_points(), and random_morphing_points(), all defined in the madminer.sampling module.
Here we’ll train a likelihood estimator with the SCANDAL method, so we focus on the extract_samples_train_density() function. We’ll sample the numerator hypothesis in the likelihood ratio with 1000 points drawn from a Gaussian prior, and fix the denominator hypothesis to the SM.
Note the keyword sample_only_from_closest_benchmark=True, which makes sure that for each parameter point we only use the events that were originally (in MG) generated from the closest benchmark. This reduces the statistical fluctuations in the outcome quite a bit.
x, theta, t_xz, _ = sampler.sample_train_density(
theta=sampling.random_morphing_points(10000, [('gaussian', 0., 0.5), ('gaussian', 0., 0.5)]),
n_samples=500000,
folder='./data/samples',
filename='train_density',
sample_only_from_closest_benchmark=True,
)
03:42 madminer.sampling INFO Extracting training sample for non-local score-based methods. Sampling and score evaluation according to (u'random_morphing_points', (10000, [(u'gaussian', 0.0, 0.5), (u'gaussian', 0.0, 0.5)]))
03:42 madminer.sampling INFO Starting sampling serially
03:42 madminer.sampling WARNING Large statistical uncertainty on the total cross section when sampling from theta = [0.58710176 1.2685223 ]: (0.001242 +/- 0.000441) pb (35.5351101412644 %). Skipping these warnings in the future...
03:43 madminer.sampling INFO Sampling from parameter point 500 / 10000
03:43 madminer.sampling INFO Sampling from parameter point 1000 / 10000
03:44 madminer.sampling INFO Sampling from parameter point 1500 / 10000
03:45 madminer.sampling INFO Sampling from parameter point 2000 / 10000
03:45 madminer.sampling INFO Sampling from parameter point 2500 / 10000
03:47 madminer.sampling INFO Sampling from parameter point 3000 / 10000
03:48 madminer.sampling INFO Sampling from parameter point 3500 / 10000
03:48 madminer.sampling INFO Sampling from parameter point 4000 / 10000
03:49 madminer.sampling WARNING For this value of theta, 1 / 29993 events have negative weight and will be ignored
03:49 madminer.sampling INFO Sampling from parameter point 4500 / 10000
03:50 madminer.sampling INFO Sampling from parameter point 5000 / 10000
03:50 madminer.sampling INFO Sampling from parameter point 5500 / 10000
03:51 madminer.sampling INFO Sampling from parameter point 6000 / 10000
03:52 madminer.sampling INFO Sampling from parameter point 6500 / 10000
03:53 madminer.sampling INFO Sampling from parameter point 7000 / 10000
03:53 madminer.sampling INFO Sampling from parameter point 7500 / 10000
03:54 madminer.sampling INFO Sampling from parameter point 8000 / 10000
04:55 madminer.sampling INFO Sampling from parameter point 8500 / 10000
05:16 madminer.sampling INFO Sampling from parameter point 9000 / 10000
05:17 madminer.sampling INFO Sampling from parameter point 9500 / 10000
05:18 madminer.sampling INFO Sampling from parameter point 10000 / 10000
05:18 madminer.sampling INFO Effective number of samples: mean 637.1639228954328, with individual thetas ranging from 11.197537298152856 to 28628.63290722551
For the evaluation we’ll need a test sample:
_ = sampler.sample_test(
theta=sampling.benchmark('sm'),
n_samples=1000,
folder='./data/samples',
filename='test'
)
05:18 madminer.sampling INFO Extracting evaluation sample. Sampling according to sm
05:18 madminer.sampling INFO Starting sampling serially
05:18 madminer.sampling INFO Sampling from parameter point 1 / 1
05:18 madminer.sampling INFO Effective number of samples: mean 10015.0, with individual thetas ranging from 10015.0 to 10015.0
2. Train likelihood estimator#
It’s now time to build the neural network that estimates the likelihood ratio. The central object for this is the madminer.ml.ParameterizedRatioEstimator class. It defines functions that train, save, load, and evaluate the estimators.
In the initialization, the keywords n_hidden and activation define the architecture of the (fully connected) neural network:
estimator = LikelihoodEstimator(
n_mades=3,
n_hidden=(60,60),
activation="relu"
)
To train this model we will minimize the SCANDAL loss function described in “Mining gold from implicit models to improve likelihood-free inference”.
estimator.train(
method='scandal',
theta='data/samples/theta_train_density.npy',
x='data/samples/x_train_density.npy',
t_xz='data/samples/t_xz_train_density.npy',
alpha=10.,
n_epochs=10,
initial_lr=0.01,
)
estimator.save('models/scandal')
05:18 madminer.ml INFO Starting training
05:18 madminer.ml INFO Method: scandal
05:18 madminer.ml INFO alpha: 10.0
05:18 madminer.ml INFO Batch size: 128
05:18 madminer.ml INFO Optimizer: amsgrad
05:18 madminer.ml INFO Epochs: 10
05:18 madminer.ml INFO Learning rate: 0.01 initially, decaying to 0.0001
05:18 madminer.ml INFO Validation split: 0.25
05:18 madminer.ml INFO Early stopping: True
05:18 madminer.ml INFO Scale inputs: True
05:18 madminer.ml INFO Shuffle labels False
05:18 madminer.ml INFO Samples: all
05:18 madminer.ml INFO Loading training data
05:18 madminer.utils.vario INFO Loading data/samples/theta_train_density.npy into RAM
05:18 madminer.utils.vario INFO Loading data/samples/x_train_density.npy into RAM
05:18 madminer.utils.vario INFO Loading data/samples/t_xz_train_density.npy into RAM
05:18 madminer.ml INFO Found 500000 samples with 2 parameters and 3 observables
05:18 madminer.ml INFO Setting up input rescaling
05:18 madminer.ml INFO Rescaling parameters
05:18 madminer.ml INFO Setting up parameter rescaling
05:18 madminer.ml INFO Training model
05:18 madminer.utils.ml.tr INFO Training on CPU with single precision
05:19 madminer.utils.ml.tr INFO Epoch 1: train loss 4.92008 (nll: 3.866, mse_score: 0.105)
05:19 madminer.utils.ml.tr INFO val. loss 4.88054 (nll: 3.877, mse_score: 0.100)
05:20 madminer.utils.ml.tr INFO Epoch 2: train loss 4.81460 (nll: 3.866, mse_score: 0.095)
05:20 madminer.utils.ml.tr INFO val. loss 4.74922 (nll: 3.872, mse_score: 0.088)
05:21 madminer.utils.ml.tr INFO Epoch 3: train loss 4.70997 (nll: 3.839, mse_score: 0.087)
05:21 madminer.utils.ml.tr INFO val. loss 4.68496 (nll: 3.835, mse_score: 0.085)
05:22 madminer.utils.ml.tr INFO Epoch 4: train loss 4.66875 (nll: 3.823, mse_score: 0.085)
05:22 madminer.utils.ml.tr INFO val. loss 4.61774 (nll: 3.826, mse_score: 0.079)
05:23 madminer.utils.ml.tr INFO Epoch 5: train loss 4.62898 (nll: 3.815, mse_score: 0.081)
05:23 madminer.utils.ml.tr INFO val. loss 4.59818 (nll: 3.813, mse_score: 0.078)
05:24 madminer.utils.ml.tr INFO Epoch 6: train loss 4.60716 (nll: 3.809, mse_score: 0.080)
05:24 madminer.utils.ml.tr INFO val. loss 4.59749 (nll: 3.814, mse_score: 0.078)
05:25 madminer.utils.ml.tr INFO Epoch 7: train loss 4.59577 (nll: 3.806, mse_score: 0.079)
05:25 madminer.utils.ml.tr INFO val. loss 4.57310 (nll: 3.807, mse_score: 0.077)
05:26 madminer.utils.ml.tr INFO Epoch 8: train loss 4.58374 (nll: 3.806, mse_score: 0.078)
05:26 madminer.utils.ml.tr INFO val. loss 4.56814 (nll: 3.808, mse_score: 0.076)
05:27 madminer.utils.ml.tr INFO Epoch 9: train loss 4.58109 (nll: 3.804, mse_score: 0.078)
05:27 madminer.utils.ml.tr INFO val. loss 4.56638 (nll: 3.807, mse_score: 0.076)
05:28 madminer.utils.ml.tr INFO Epoch 10: train loss 4.57864 (nll: 3.804, mse_score: 0.077)
05:28 madminer.utils.ml.tr INFO val. loss 4.56464 (nll: 3.806, mse_score: 0.076)
05:28 madminer.utils.ml.tr INFO Early stopping did not improve performance
05:28 madminer.utils.ml.tr INFO Training time spend on:
05:28 madminer.utils.ml.tr INFO initialize model: 0.00h
05:28 madminer.utils.ml.tr INFO ALL: 0.16h
05:28 madminer.utils.ml.tr INFO check data: 0.00h
05:28 madminer.utils.ml.tr INFO make dataset: 0.00h
05:28 madminer.utils.ml.tr INFO make dataloader: 0.00h
05:28 madminer.utils.ml.tr INFO setup optimizer: 0.00h
05:28 madminer.utils.ml.tr INFO initialize training: 0.00h
05:28 madminer.utils.ml.tr INFO set lr: 0.00h
05:28 madminer.utils.ml.tr INFO load training batch: 0.02h
05:28 madminer.utils.ml.tr INFO fwd: move data: 0.00h
05:28 madminer.utils.ml.tr INFO fwd: check for nans: 0.01h
05:28 madminer.utils.ml.tr INFO fwd: model.forward: 0.06h
05:28 madminer.utils.ml.tr INFO fwd: calculate losses: 0.00h
05:28 madminer.utils.ml.tr INFO training forward pass: 0.06h
05:28 madminer.utils.ml.tr INFO training sum losses: 0.00h
05:28 madminer.utils.ml.tr INFO opt: zero grad: 0.00h
05:28 madminer.utils.ml.tr INFO opt: backward: 0.04h
05:28 madminer.utils.ml.tr INFO opt: clip grad norm: 0.00h
05:28 madminer.utils.ml.tr INFO opt: step: 0.01h
05:28 madminer.utils.ml.tr INFO optimizer step: 0.06h
05:28 madminer.utils.ml.tr INFO load validation batch: 0.01h
05:28 madminer.utils.ml.tr INFO validation forward pass: 0.02h
05:28 madminer.utils.ml.tr INFO validation sum losses: 0.00h
05:28 madminer.utils.ml.tr INFO early stopping: 0.00h
05:28 madminer.utils.ml.tr INFO report epoch: 0.00h
05:28 madminer.ml INFO Saving model to models/scandal
(nll: 3.830, mse_score: 0.064
3. Evaluate likelihood estimator#
estimator.evaluate_log_likelihood(theta,x) estimated the log likelihood for all combination between the given phase-space points x and parameters theta. That is, if given 100 events x and a grid of 25 theta points, it will return 25*100 estimates for the log likelihood, indexed by [i_theta,i_x].
theta_each = np.linspace(-1.,1.,25)
theta0, theta1 = np.meshgrid(theta_each, theta_each)
theta_grid = np.vstack((theta0.flatten(), theta1.flatten())).T
np.save('data/samples/theta_grid.npy', theta_grid)
estimator.load('models/scandal')
log_p_hat, _ = estimator.evaluate_log_likelihood(
theta='data/samples/theta_grid.npy',
x='data/samples/x_test.npy',
evaluate_score=False
)
05:28 madminer.ml INFO Loading model from models/scandal
05:28 madminer.utils.vario INFO Loading data/samples/theta_grid.npy into RAM
05:28 madminer.utils.vario INFO Loading data/samples/x_test.npy into RAM
05:28 madminer.ml INFO Starting ratio evaluation for 625000 x-theta combinations
05:28 madminer.ml INFO Evaluation done
Let’s look at the result:
bin_size = theta_each[1] - theta_each[0]
edges = np.linspace(theta_each[0] - bin_size/2, theta_each[-1] + bin_size/2, len(theta_each)+1)
fig = plt.figure(figsize=(6,5))
ax = plt.gca()
expected_llr = np.mean(log_p_hat,axis=1)
best_fit = theta_grid[np.argmin(-2.*expected_llr)]
cmin, cmax = np.min(-2*expected_llr), np.max(-2*expected_llr)
pcm = ax.pcolormesh(edges, edges, -2. * expected_llr.reshape((25,25)),
norm=matplotlib.colors.Normalize(vmin=cmin, vmax=cmax),
cmap='viridis_r')
cbar = fig.colorbar(pcm, ax=ax, extend='both')
plt.scatter(best_fit[0], best_fit[1], s=80., color='black', marker='*')
plt.xlabel(r'$\theta_0$')
plt.ylabel(r'$\theta_1$')
cbar.set_label(r'$\mathbb{E}_x [ -2\, \log \,\hat{r}(x | \theta, \theta_{SM}) ]$')
plt.tight_layout()
plt.show()
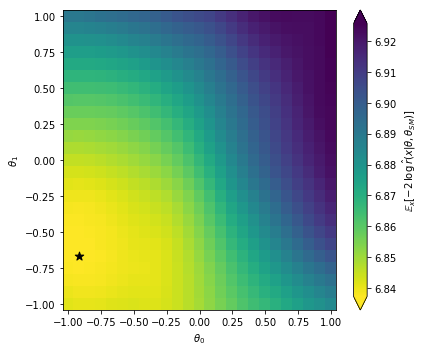
Note that in this tutorial our sample size was very small, and the network might not really have a chance to converge to the correct likelihood function. So don’t worry if you find a minimum that is not at the right point (the SM, i.e. the origin in this plot). Feel free to dial up the event numbers in the run card as well as the training samples and see what happens then!